James Crossland
Digital Marketing Manager | Kerv digital
Have a question?
Get in touchPublished 06/07/22 under:
Everything you ever wanted to know about Data Gravity, including the answer to the question… What is Data Gravity?
What Is Data Gravity?
First of all, lets answer the question ‘what is Data Gravity?’
The term Data Gravity was first coined by a man named Dave McRory as an analogy between how data in IT systems attracts more data and apps and how objects with more mass, in real life, will attract those with less.
Data Gravity then, is the process in which large amounts of data in a network, system or an
organisations processes will attract more applications, services or additional data to itself.
The gravity analogy comes into play because, as more data is stored, more software or business processes will grow around it, in turn attracting more data, in turn drawing in more applications at an ever increasing frequency.
It’s also worth noting that, when coining the phrase, Dave McRory made a distinction between naturally occurring Data Gravity and Artificial Data Gravity, which he defined as occurring through a result of external forces such as legislation, throttling and manipulative pricing.
In practical terms, the further spread out data is, perhaps over different systems or networks, the more it will impact on the ability of users or applications to utilise it effectively.
To maximise work efficiency then, it makes sense for an organisation to store all their data in one, easily accessed location, with any associated applications, services or business processes attached to it in the same place.
It’s also worth noting that from the perspective of representing your business as a going concern, the more date you hold in a particular repository, the greater it’s perceived value will be, both commercially and in terms of the results analytic tools and AI can spin out with it.
If you’re looking to digitally transform your business (or perhaps more ambitiously digitally disrupt your sector), Data Gravity is an issue you’re going to need to consider at a strategic and technological level.
At a strategic level, its an issue that will affect the sequence that you approach your transformation from you want it to be a sustainable effort.
At a technological level, its selecting the right technology platform to ensure you don’t back yourself into a corner.
Any organisation operating today will generate a tremendous amount of data, often to an extent where it’s unrealistic to manage it with a traditional approach to CMS’s or analytics. This is because data analytic platforms tend to live in their own hardware/software stacks and the data they use will be accessed through direct-attached storage (DAS).
A lot of analytic platforms though (Splunk, Hadoop, TensorFlow etc) like to ‘own’ their data which means for any large scale digital transformation, wholesale data consolidation and migration becomes essential before you can run any really cool analytics, AI or ML on it.
Benefiting From Data Gravity
The first thing you’ll need to realise with data gravity is that you can’t stop it. Much as gravity is a fundamental law of physics, data gravity is a phenoma to be understand and used to inform your digital transformation.
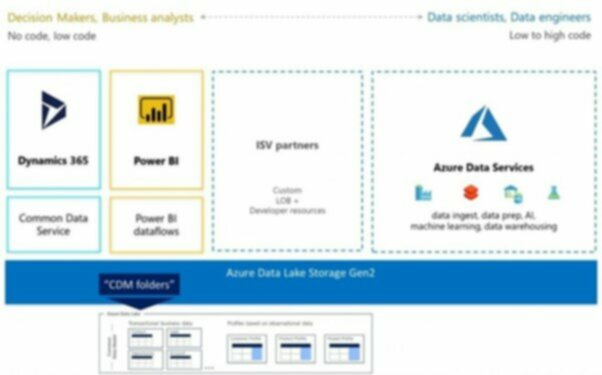
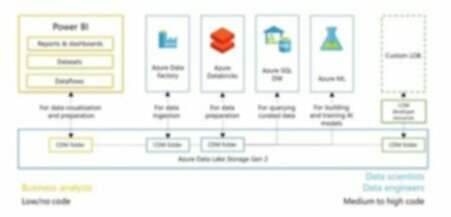
Choose a platform such as Azure that has a range data storage option such as Azure SQL, DataLake, CosmoDB; data processing options such as Databricks, Python, Data Factory; data visualisation and analysis options such as PowerBI, Python, Azure Analysis; and AI capabilities in Azure ML; to let you build an architecture for consolidating your data in a way that lets you start small but scaling up fast. Once in place your organisation will be in a much stronger position to bring advanced analytics and AI to bear on it.
System Scalability For Data Gravity
It should be an obvious point (but it’s normally the obvious ones that get overlooked isn’t it?); when architecting out a system or network with the idea of data gravity its core feature should be scalability.
If the whole point is to gather data at exponential rates, then your architecture will need to be able to handle that. You’ll also want a solution in which personnel and infrastructure costs don’t scale with your increases in data.
This is where a Cloud Based solution becomes your friend and where Kerv Digital are happy to step in and advise you on your best course of action.
Future Proofing & Data Gravity
It sometimes feels like Data analytic apps and AI/ML platforms change on a weekly basis, which obviously needs to be considered for any end solution. The data must be accessible across multiple platforms, be built to open standards and adhere to compliance standards, including any your organisation currently use but also, any they might use in the future.
Data Gravity Key Take Away’s…
- Data Gravity will occur no matter what you do
- The more data you have in one place the more powerful it will become
- If your organisation’s data is spread around different, discrete, networks and systems it’ll be more costly to access and utilise, much harder to secure and exponentially harder to analyse as your transformation continues.
Kerv Digital’s recommend solutions based in Microsoft Azure. Data Lake is already architected to help you tame your data gravity by giving you tools such as Data Factory to perform ETL processes that fetch your data from disparate sources into one place.
Similarly CDS, part of PowerPlatform, allows you to centralise all your app data into one place to create maximum gravity for building your Apps, RPA, or BI from it.