

Ed Yau
Principal Architect - Data Solutions | Kerv Digital
Have a question?
Get in touchPublished 06/07/22 under:
A workaround for ADF/Synapse pipelines when using the Execute Pipeline activity to inspect anything about the run from the calling pipeline
A longstanding issue I’ve found with ADF/Synapse pipelines is that if you try to use the Execute Pipeline activity, then it won’t really let you inspect anything about the run from the calling pipeline.
This can be generalised to state that within any individual pipeline, you’ll never really be able to understand much about other pipeline runs.
There’s actually a big Azure Feedback post about this, but unfortunately no one seems to have come up with any kind of workaround… So, here’s my workaround…
Just call the Synapse/Data Factory API from within the pipeline!
Setup the Rest API as a LinkedService:
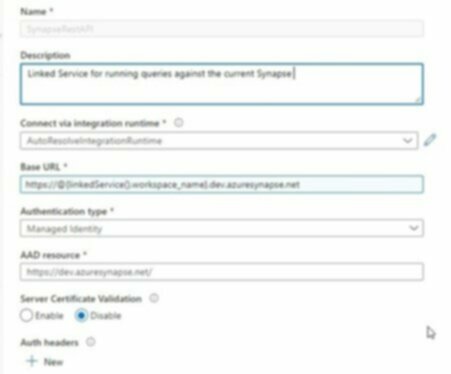
- Auth type = Managed Identity. It’s worth noting that AAD Resource is not the usual endpoint used for managed identity authentication (see this note)
- For the base URL, just have workspace_name as a parameter for the linked service. This will be used later and will make this linked service agnostic to the environment you’re in.
Then create a dataset from this:
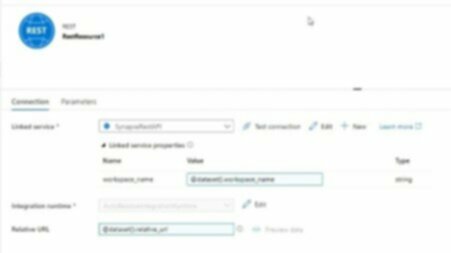
As you can tell, I’m being really generic here and just passing the relative url through for now.
Again, it’s worth noting that workspace_name is a parameter here… we only define it in the actual pipeline.
Et voila!
Now we have a dataset we can use to get data from the Data Factory API. e.g.:
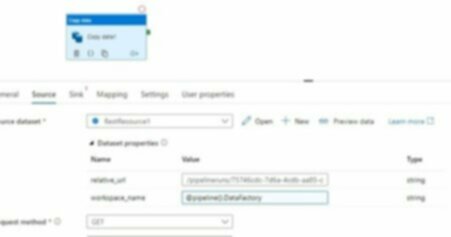
As you can now see, we can pass in the workspace name, so this linked service can be moved to new environments with no issue!
I actual had to do a double take when I first hit preview data…
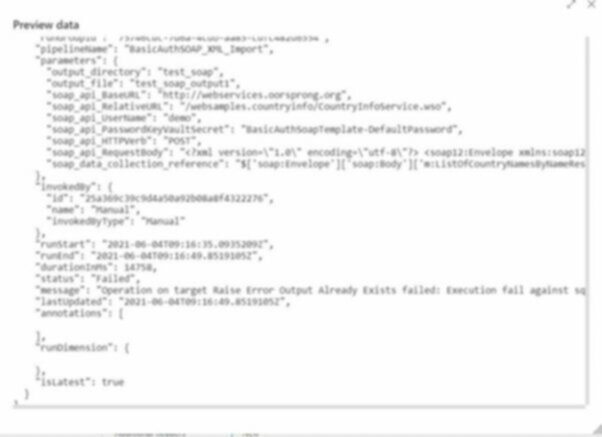
We can now easily get the top level output of a run.
“But what about details of the inner activities” you ask…?
Glad you did! Just use this method and hey presto, we now have all the details of our pipeline run…

Since this is a REST dataset, we unfortunately can’t use it immediately in a Lookup or Get Metadata activity… but, we can easily persist this to a storage account, then look it up and understand anything about how our pipeline ran, from within a pipeline!
This was fun little workaround to create and saved me from a jam.
As I couldn’t find anyone else talking about having done this, I thought I’d leave it here in case you found it useful.





